
Overview
Local Host Cache and Service Continuity should be at the forefront of conversations when building a resilient Citrix environment.
Local Host Cache and Service Continuity are Citrix technologies that can maintain end-user access to business-critical workloads during potential service disruptions. While they function differently, both features serve the same purpose: to keep users launching their apps and desktops regardless of service health.
Let's start by differentiating the 2 features:
- Local Host Cache (LHC): LHC leverages a locally cached copy of the Site database hosted on Cloud Connectors. The local copy of the Site database is used to broker sessions if connectivity between the Cloud Connectors and Citrix Cloud is lost. LHC is enabled by default for DaaS environments, but some configurations must be considered to ensure LHC works properly during a service disruption.
-
Service Continuity: Service Continuity is a DaaS-only feature that uses Connection Lease files downloaded to a user’s endpoint when they login to Citrix Workspace from either the Workspace app or a browser (the Citrix Workspace web extension is required for Service Continuity to work in a browser). Service Continuity uses the Connection Lease files when a normal end-user launch path cannot be established. It’s important to note that Service Continuity can leverage the LHC database on the Cloud Connectors, so many of the LHC misconfigurations below can also impact customers using Service Continuity for resiliency. Service Continuity is only supported for DaaS connections through the Workspace service. Service Continuity cannot be used with an on-premises StoreFront server.
Understanding the resiliency features is a critical first step in configuring your environment correctly in the case of a service disruption. This article assumes a working knowledge of LHC and Service Continuity.
There are a few crucial configurations to check for to ensure that users can continue to access their resources when LHC or Service Continuity activates. The table below lists common misconfigurations that may impact the availability of DaaS resources in the event of a service disruption. Review this list and update any potential misconfigurations in your environment before it’s too late!
Impacts All Access Methods
In the table below, you’ll see that some misconfigurations impact StoreFront only, some impact Workspace only, and some can impact both. That’s because, with Service Continuity, the Cloud Connectors still attempt to retrieve the VDA addresses from the Citrix Cloud-hosted session broker (using the information supplied from the cached connection leases on the endpoint). If the session broker is unreachable, the VDA addresses are determined using the LHC database. You can see the entire process here in more detail.
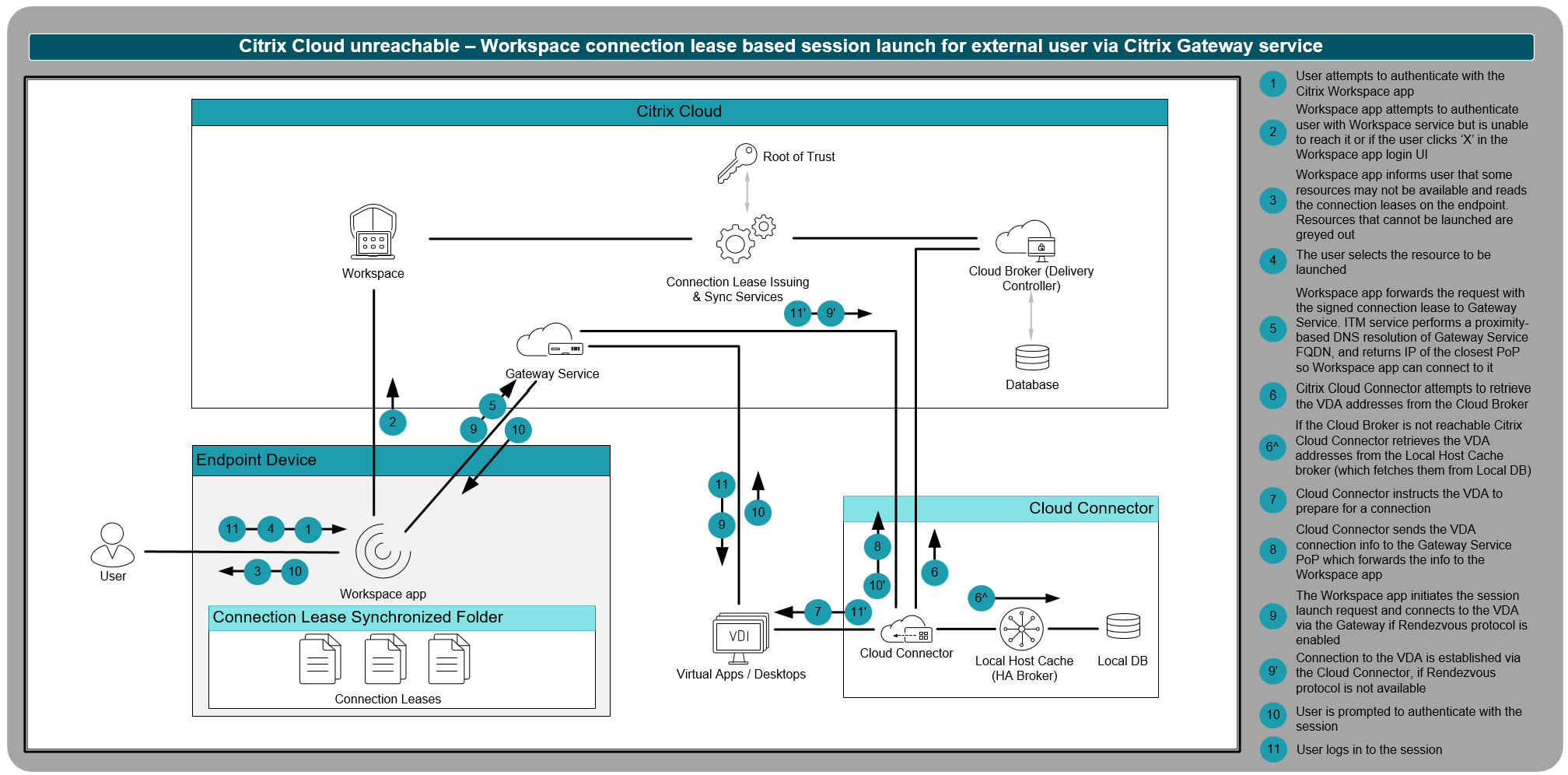{kind=link}
|
Misconfiguration |
Description |
Impact |
Detection |
Mitigation |
|
Pooled single-session OS VDAs that are power managed are unavailable during LHC |
Because power management services reside on Citrix Cloud infrastructure rather than Cloud Connectors, power management becomes unavailable during an LHC event. This results in an inability to reboot power-managed pooled single-session OS VDAs and reset their differencing/write cache disks while LHC is active. For security reasons, these VDAs are unavailable by default during LHC to avoid changes and data from previous user sessions being available on subsequent sessions. |
Pooled single-session VDAs in power-managed delivery groups are unavailable during LHC events. |
Review the Delivery Groups node in Studio. Any pooled single-session delivery group that is power-managed and is not configured for access during LHC will show a warning icon. |
Edit the Local Host Cache settings within the delivery group. Note: Changing the default can result in changes and data from previous user sessions being present in subsequent sessions. |
|
Too many VDAs in a Resource Location |
The LHC broker on Cloud Connectors caps VDA registrations at 10,000 per resource location if the resource location goes into LHC mode. |
More than 10,000 VDAs in a resource location can result in excessive load on Cloud Connectors. This can result in stability issues and a subset of VDAs being unavailable during LHC. |
Review the Zones node to see if any alerts are detected. If your environment has too many VDAs in a resource location, a warning icon will show on the resource location (check out the Troubleshoot tab at the bottom of the Zones node after clicking the resource location to learn more about the errors and warnings in that resource location). |
Reconfigure Resource Locations to contain no more than 10,000 VDAs. |
|
3 Consecutive failed config syncs |
Cloud Connectors periodically sync configurations from Citrix Cloud to the local database to ensure up-to-date configurations if LHC activates. |
Failed configuration syncs can result in stale or corrupted configurations used in case of an LHC event. |
Monitor Cloud Connectors for 505 events from the Config Synchronizer Service. Email alerts for failed config syncs are on the roadmap for Citrix Monitor! |
Review firewall configurations to ensure your firewall accepts XML and SOAP traffic. Review CTX238909. Open a support ticket to determine why config sync failures occur in your environment. |
|
Multiple elected brokers |
One Connector per Resource Location should be elected for LHC events. Cloud Connectors must be able to communicate with each other to determine the elected broker and understand the health of other peer connectors to make a go/no-go decision about entering LHC mode. |
“Split brain” scenario where multiple Connectors in the same Resource Location remain active during an LHC event. VDAs may register with any elected connectors in the Resource Location, and launches may fail intermittently while LHC is active. |
Monitor Connectors for 3504 events from the High Availability Service. Review to see if more than one Connector per Resource Location is being elected. |
Ensure Connectors can communicate with each other at http://<FQDN_OF_PEER_CONNECTOR>:80/Citrix/CdsController/ISecondaryBrokerElection. If using a proxy, bypassing the proxy for traffic between Connectors is recommended. |
|
Lack of Regular Testing |
It’s debatable whether a lack of testing can be considered a misconfiguration, but what’s not up for debate is the impact testing can have on ensuring this tech works in your environment! Testing can ensure infrastructure is scaled properly and works as expected before a disruption occurs. Testing should be done at regular intervals. For testing LHC, see Force an Outage. Forcing LHC is relevant to both on-prem StoreFront customers and customers leveraging Service Continuity. |
DaaS resources are potentially inaccessible during a service disruption. |
If you don’t have a testing plan for LHC or Service Continuity in your environment, consider this misconfiguration detected. Verify that Local Host Cache is working. |
Create a testing plan to test Service Continuity and Local Host Cache regularly. |
|
Low vCPU cores per socket configuration |
LHC operates using a Microsoft SQL Server Express LocalDB on the Cloud Connector. Microsoft has a limitation on SQL Express in which the Connector is limited to the lesser of 1 socket or 4 vCPU cores when using the LHC DB. If we configure Cloud Connectors to use one core per socket (e.g., 4 sockets, 4 cores), we limit LHC operating on a single core during an LHC event. Because all VDA registration and brokering operations go through a single connector during LHC, this can negatively impact performance and cause issues with VDA registration during the service disruption. More info regarding LHC core and socket configurations can be found in the Recommended compute configuration for Local Host Cache. |
Negative impact on the stability of VDA re-registration during an LHC event and the performance of LHC brokering operations. |
Check Task Manager to view core and socket configurations. Divide the number of virtual processors by the number of sockets to get your core-per-socket ratio. |
Reconfigure your VM to use at least 4 cores per socket. A new instance type may have to be used for public cloud workloads. Rebooting your connector may be required to reconfigure the core and socket configuration. |
|
Undersized Cloud Connectors |
During an event in which LHC activates, a single Cloud Connector per resource location begins to broker sessions. The elected LHC broker handles all VDA registrations and session launch requests (see Resource locations with multiple Cloud Connectors for more information on the election process). Sizing connectors to handle this added load during an LHC event is important for ensuring consistent performance. |
Negative impact on stability and performance during LHC VDA registration and LHC steady state. |
Check out the Zones node within Citrix DaaS Web Studio! If your environment has undersized connectors, https://docs.citrix.com/en-us/citrix-daas/manage-deployment/zones.html#troubleshooting. The sizing of connectors can also be checked on each connector machine at the hypervisor or VM level. |
Reconfigure connectors to have at least 4 vCPU and 6 GB of RAM. Review the Recommended compute configuration for local host cache for recommended sizing guidelines based on the number of VDAs in the Resource Location. |
|
Multiple Active Directory (AD) domains in a single resource location |
As per Citrix DaaS limits e-docs, only one Active Directory domain is supported per resource location. Issues may arise if you have multiple Cloud Connectors in a zone and the connectors are in different AD domains. |
Multiple AD domains in a single Resource Location can cause issues with VDA registration during LHC events. VDAs may have to try multiple Connectors before finding one they can register with. This can impact VDA registration times and add additional load on Connectors when VDAs must register, especially in VDA registration storms like Local Host Cache re-registration or Autoscale events. |
If your environment has multiple AD domains in a resource location, a warning icon will show on the resource location (check out the “Troubleshoot” tab at the bottom of the Zones node after clicking the Resource Location to learn more about the errors and warnings in that Resource Location). If you click the zone, it will show you the FQDN of the connectors within the zone. |
Reconfigure resource locations to only contain connectors in a single AD domain per resource location.
|
Impacts Workspace
The following misconfigurations only apply when Workspace is used as the access tier.
|
Misconfiguration |
Description |
Impact |
Detection |
Mitigation |
|
Service Continuity not enabled |
Things can’t work if they’re not turned on! Service Continuity is a core resiliency feature for customers leveraging Citrix Workspace service as their access tier. You can manage Service Continuity on the Citrix Cloud Workspace configuration page. |
Without Service Continuity enabled, Connection Lease files won’t be downloaded, and users won’t be able to access their apps and desktops during a service disruption. |
View the Service Continuity tab in the Citrix Cloud Workspace configuration page to see if the feature is enabled. |
Enable Service Continuity. See Configure Service Continuity for more information. |
|
Access clients are unsupported for Service Continuity |
To download Service Continuity Connection Lease files, users must access their Workspace from a client that supports Service Continuity. See User device requirements to learn which client versions and access scenarios are supported. |
Users accessing from clients that do not support Service Continuity will be unable to launch DaaS resources during a service disruption. |
Review session launches in Monitor for Workspace app versions. |
Update Citrix Workspace app clients to versions that support Service Continuity. Encourage users using the web browser to install the Citrix Workspace web extension. |
Impacts StoreFront
The following misconfigurations only apply when StoreFront is used as the access tier.
|
Misconfiguration |
Description |
Impact |
Detection |
Mitigation |
|
StoreFront ‘Advanced Health Check’ setting not configured |
StoreFront’s Advanced Health Check feature gives StoreFront additional information about the Resource Location where a published app or desktop can be launched. |
Without Advanced Health Check, StoreFront may send launch requests to a Resource Location that does not deliver that particular resource, resulting in intermittent launch failures during an LHC event. |
On StoreFront, run “Get-STFStoreFarmConfiguration” via PowerShell. Automated detection of the StoreFront Advanced Health Check feature is on our roadmap for Web Studio! |
Enable the StoreFront Advanced Health Check feature. For StoreFront 2308 forward, StoreFront Advanced Health Check is enabled by default. If you upgrade your StoreFront to the 2024 LTSR once it is released, Advanced Health Check will be enabled automatically. |
|
Incorrect load balancing monitor |
Some customers opt to use a load-balancing vServer to balance XML traffic between StoreFront and Connectors for optimized manageability and traffic management. When connectors in a resource location go into LHC, only the primary broker can service launch requests. The remaining Connectors send health checks to try to reconnect again. If an incorrect monitor is used on the load balancing server, StoreFront may continue to send launch requests to all connectors in the resource location rather than just the elected broker. |
Potential intermittent launch failures during an LHC event. |
Check your load balancer to ensure the monitor bound to the load balancer is monitoring for brokering capabilities, not just TCP responses. NetScaler has this functionality out of the box with the CITRIX-XD-DDC monitor. Note: The CITRIX-XML-SERVICE monitor is for previous versions of Citrix Virtual Apps and Desktops and does not perform the same checks as the CITRIX-XD-DDC monitor. |
Configure your load balancing vServer to monitor Connectors based on brokering capabilities (e.g., use the CITRIX-XD-DDC monitor for connector load balancing). |
|
Connectors not listed as a single set of resource feed in StoreFront |
With the addition of StoreFront’s Advanced Health Check feature, Citrix recommends that all Cloud Connectors within a single Cloud tenant be included as a single set of Delivery Controllers in StoreFront. Check out this Citrix TIPs blog for more information regarding recommended configurations. |
Duplicate icons for end users or more complex multi-site aggregation configurations are required in StoreFront. |
View your resource feed configuration in the “Manage Delivery Controllers” tab in StoreFront. |
Configure all Connectors (or all Connector load balancing vServers) are listed as a single Site within StoreFront. Review Add resource feeds for Desktops as a Service for more information. |
|
Tags used to restrict launches to a subset of Resource Locations in a Delivery Group |
With Advanced Health Check, StoreFront knows what resource locations a published app or desktop can launch from. StoreFront does this using Delivery Group to Machine Catalog mappings. However, StoreFront is not aware of tags. Consider a scenario in which a Delivery Group contains Machine Catalogs from Resource Location “A” and Resource Location “B”. If we use tags to restrict app/desktop launches to only Resource Location “A”, StoreFront will continue to send launch requests to both Resource Location “A” and “B” during an LHC event because it does not have tag information. |
Potential intermittent launch failures during LHC events. |
Review tags used in your environment. Automated detection of Resource Location-based tag restrictions is on our roadmap for Web Studio! |
Configure tags so that at least one (preferably multiple!) VDA in each Resource Location delivered from a Delivery Group contains each tag. |
|
Not all connectors are receiving Secure Ticket Authority (STA) requests |
A subset of connectors in a resource location are not receiving STA requests from StoreFront. This can be because either they are not listed in StoreFront or there is another problem with communication, such as an expired certificate on the connector. |
During a Local Host Cache event, a single Connector acts as the STA server for the Resource Location. If the elected broker is not receiving STA traffic, all launches through a NetScaler could fail during an LHC event. |
Check that all connectors are listed as STAs on your StoreFront and NetScaler Gateway servers. Automated detection of STA traffic is on our roadmap for Web Studio! |
View NetScaler Gateway configurations in StoreFront and ensure all Connectors are listed as STA servers. Review NetScaler appliances and ensure all STAs listed in StoreFront are in the same format in the NetScaler Gateway vServers. STA service health can also be monitored in the Gateway vServer. |
|
StoreFront not communicating with all Cloud Connectors |
StoreFront can only contact a subset of connectors in a resource location. This can be because either they are not listed in StoreFront or there is another problem with communication, such as an expired certificate on the connector. |
StoreFront not communicating with a subset of Cloud Connectors can negatively impact the scalability and performance of an environment during both steady-state and LHC operations. If the elected broker is not receiving StoreFront traffic, all LHC launch attempts may fail. |
Review the resource feeds in StoreFront to ensure that all connectors are listed. If so, test that StoreFront can communicate with all listed connectors over the port configured in the resource feed. Automated detection of StoreFront traffic is on our roadmap for Web Studio! |
Add all connectors to the resource feed in StoreFront and fix any communication issues between StoreFront and the connectors. One of the most common communication issues between StoreFront and connectors is an expired certificate on the connector when XML traffic is over port 443. Note: For customers with many connectors, it may be beneficial to configure load-balancing vServers for each resource location to reduce the management overhead and simplify troubleshooting. Review Citrix TIPs: Integrating Citrix Virtual Apps and Desktops service and StoreFront for more information. |
Summary
Correctly configuring your Citrix environment significantly impacts its availability and performance. Review your environments for these potential misconfigurations to keep your business running, no matter what!
There are no comments to display.
Create an account or sign in to comment
You need to be a member in order to leave a comment
Create an account
Sign up for a new account in our community. It's easy!
Register a new accountSign in
Already have an account? Sign in here.
Sign In Now